El Monte Carlo Tree Search, más conocido como MTCS, es una
técnica de inteligencia artificial en la que se mezcla dos técnicas muy
populares dentro de este campo:
1º Árboles Clásicos de Decisión.
2º Aprendizaje Por Refuerzo (Q-Learning).
Este algoritmo tiene
dos fases destacadas:
Fase de exploración, en la que el agente prueba diferentes
situaciones ante el mismo estado y observa que pasa al tomar esa decisión, es
decir, cuanto de buena es esa decisión para nuestro objetivo.
Y una fase de explotación, en la que el agente prueba
continuamente las decisiones mejores para ver si realmente sirven para alcanzar
nuestro objetivo. Y así cambiar las decisiones por otras que son mejores.
Entonces el agente tiene que:
1º Explorar todas las opciones potenciales en ese tiempo.
2º Identificar rápidamente cual es la mejor.
3º Tener en cuenta las otras opciones buenas para validar
como es de buena la mejor.
Utilizando la técnica del Min Max tenemos el problema de que
si el árbol es muy grande escala muy mal con respecto al coste computacional.
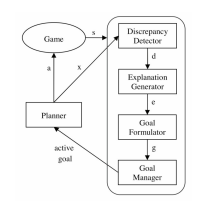
Para el ajuste de los pesos de los nodos de nuestro MTCS
tenemos los procesos de Selección, expansión, simulación y “Backpropagation”
(Recalculo de abajo a arriba de los pesos de cada nodo según si la decisión
final ha sido buena o mala).
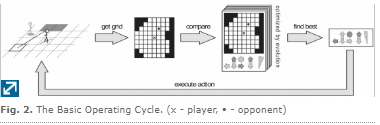
Unos ejemplos visuales de cada una de estas fases serian:


La fórmula matemática que encontramos dentro de este
algoritmo seria la UCT (Upper Confidence Bound 1 applied to trees):
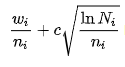
En la que el nodo que tenga el valor mayor a la hora de aplicarle
esta fórmula será el que el se elegirá como decisión.
La fórmula esta compuesta de:
Wi = número de victorias después de haber cogido este nodo.
ni = número de simulaciones de ese nodo.
Ni = número total de simulaciones de nodos parentales.
c = parámetro de exploración por lo general suele ser √2.
Referencias de: