Información sobre Agentes de Russel y
Norvig:
Agentes y su entorno
Definición de Agente: Un agente es cualquier cosa capaz de percibir su
medioambiente con la ayuda de sensores y actuar en ese medio utilizando
actuadores.
El término de percepción se refiere a las entradas que puede recibir
nuestro agente en cualquier momento. Hablaremos de secuencia de percepciones
como el conjunto de todas las anteriores percepciones hasta la actual.
Por lo que un agente toma una decisión en un instante dependiendo de la
secuencia completa hasta ese instante.
En conclusión, un agente utiliza una función “Decisión” que toma como
entrada una percepción y genera una acción como respuesta.
Tenemos que diferenciar entre función del agente como una descripción
matemática abstracta del programa del agente que sería la implementación
completa que ejecuta nuestro agente sobre su arquitectura.
Buen comportamiento: el concepto de racionalidad
Un agente racional es aquel que en cada elemento de la tabla que define su
función de agente se tendría rellenar correctamente.
Entendemos como concepto de correcto aquella acción que realiza el agente y
le proporciona un mejor resultado en la función que desempeña.
Por lo que nos surge la necesidad de medir este rendimiento.
Las medidas de rendimiento incluyen los criterios que determinan el éxito
en el comportamiento del agente. Cuando un agente realiza varias acciones en su
entorno lo modifica y si el resultado final es el esperado, el agente está
realizando con éxito su función.
Importante: Como normal general siempre es mejor diseñar las medidas de
utilidad de acuerdo a lo que se quiere para el entorno, que de acuerdo con cómo
se cree que el agente debe comportarse.
La racionalidad en un momento determinado depende de:
- - La medida de rendimiento que define el criterio de éxito.
- - El conocimiento acumulado por nuestro agente sobre el medio.
- - Las acciones posibles que puede realizar el agente.
- - La secuencia de percepciones que el agente lleva hasta ese momento.
Por lo tanto, un agente racional se puede definir como:
En cada posible secuencia de percepciones, un agente deberá emprender
aquella acción que supuestamente maximice su medida de rendimiento, basándose
en las evidencias aportadas por la secuencia de percepciones y en el
conocimiento que el agente mantiene almacenado.
Un agente debe ser capaz de aprender a determinar cómo tiene que compensar
el conocimiento incompleto o parcial inicial. Es decir, carece de autonomía
cuando se apoya más en el conocimiento que le proporciona su diseñador que en
sus propias percepciones.
La naturaleza del entorno:
Se denomina entorno de trabajo al conjunto formado por medidas de
rendimiento, entorno, actuadores y sensores del agente.
Notación para discusión: Conductor autónomo imposible
debido a las ilimitadas combinaciones que casos que un agente puede
encontrarse.
Se denomina softbot a aquellos agentes que no tiene una función a
desarrollar sobre entornos físicos. Por ejemplo, un softbot que revise fuentes
de información de internet.
Dentro de las propiedades a destacar de los entornos de trabajo:
-
Totalmente observable vs Parcialmente observable: En este caso el agente
podría obtener a través de sus sensores una percepción total (totalmente
observable) o solo una porción (parcialmente observable).
-
Determinista vs Estocástico: Se
denomina entorno determinista aquel en el que el agente sabe el comportamiento
(predicción) del mundo y sabe cuál va a ser su estado antes de que cambie. Si
el agente no es capaz de saber cómo cambia el mundo que lo rodea se denomina
estocástico. Existe una excepción denominada entorno estratégico en la que el
medio es determinista excepto para las acciones de otros agentes.
-
Estático vs Dinámico: Un entorno es dinámico si puede cambiar mientras el
agente está pensando que acción realizar. Por el contrario, si no cambia
mientras el agente piensa una acción se denomina Estático.
-
Episódico vs Secuencial: Se denomina entorno episódico a aquel que cuando
un agente toma una decisión no le influye en sus acciones siguientes. Por el contrario,
si las decisiones del agente se ven afectados por decisiones anteriores en el
mundo se denomina Secuencial, el claro ejemplo de este tipo sería una partida
de ajedrez.
-
Discreto vs Continuo: Si el entorno tiene un número determinado de
percepciones que genera será discreto, en el caso de que sea un número
constante de percepciones entonces será Continuo.
-
Agente Individual vs Multiagente: Dentro del entorno podemos encontrar
entornos donde solo actué un agente (Individual) y entornos donde varios
agentes actúen a la vez, pudiendo tener interacción entre ellos. Aquí salen dos
ramas: la competitiva en la que varios agentes intentan alcanzar un objetivo de
manera exclusiva. Y cooperativo en lo que los agente tienen que alcanzar un
objetivo común ayudándose si es posible unos con otros.
Estructura de los agentes:
Un agente está
conformado por una arquitectura (computador + sensores + actuadores) y un
programa (función del agente).
Los programas de los
agentes reciben percepciones de los sensores y devuelve una acción a los
actuadores.
Podemos diferenciar en 4
tipos básicos de programas para agentes:
- - Agentes Reactivos simples
- - Agentes Reactivos basados en modelos
- - Agentes basados en Objetivos
- - Agentes basados en Utilidad
1º AGENTES REACTIVOS SIMPLES:
Es el más sencillo de todos. Este agente
selecciona una acción mediante la percepción recibida, ignorando el resto de
percepciones anteriores.
Una regla de condición-acciones es:
Si ________________ entonces
_______________;
Este agente funcionara solo si los
entornos son totalmente observables, por lo que si hay una pequeña porción no
observable del entorno generara muchos problemas a nuestro agente.
Notación: para salir de bucles infinitos
de decisión es mejor otorgar la posibilidad de acción aleatoria al agente.
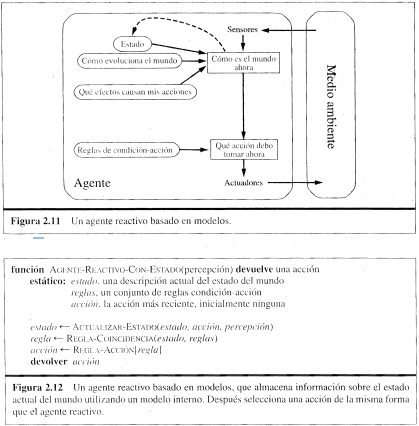
2º AGENTES REACTIVOS BASADOS EN MODELOS:
Este tipo de agentes tiene in estado
interno para almacenar las historias percibidas anteriormente y refleje algunos
aspectos no observables.
El conocimiento acerca del mundo se
denomina modelo del mundo y el agente que utilice esto se denomina agente basado
en modelos.
3º AGENTES BASADOS EN OBJETIVOS:
Para este tipo de agentes se caracteriza
porque la decisión de realizar una acción se ve condicionada por una meta que
tiene que alcanzar y habrá movimientos que favorecerán más a alcanzar ese
objetivo que otros.
Entonces nos encontramos con dos subcampos
muy importantes a la hora de satisfacer estas metas. Serian la búsqueda y la planificación.
Que hablaremos de ello más adelante.
4º AGENTES BASADOS EN UTILIDAD:
Satisfacer solo las metas no generan un
comportamiento de alta calidad, ya que para el ejemplo de la conducción de un
taxi no solo nuestro fin es llegar al objetivo. A lo mejor queremos que sea lo más
seguro posible, la más rápida, la más barata etc. Entonces necesitamos una función
de utilidad que calcule para un movimiento cuanto favorece la utilidad deseada.